Although these errors may not always pose an immediate threat to the collection we think it’s important to at least be aware of them, and to consider which are acceptable for your project and which are not.
The most common “hidden errors” we come across are as follows:
-
Incorrect coordinates for text blocks in the ALTO files.

-
Incorrect ordering of text blocks in the ALTO files, so the text on the page does not appear in reading order.

-
Incomplete OCR (i.e. pieces of text that appear on the scanned image of the page, but which were not recognized as text during the OCR process).

-
Inaccurate text blocks in the ALTO files, with lines of text that were captured across multiple columns.
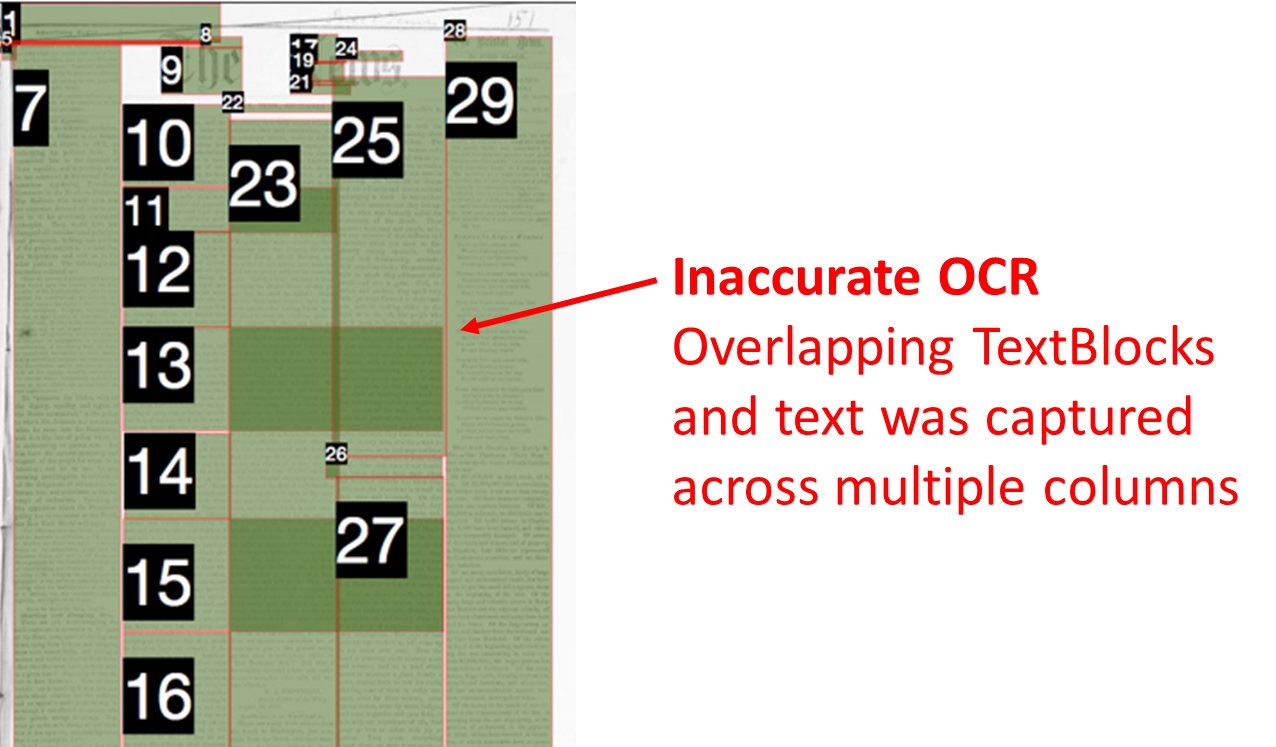
In some respects these sorts of errors in the underlying structure of the ALTO files don’t matter too much for most existing use cases. The data can still be searched and displayed in Chronicling America (http://chroniclingamerica.loc.gov) or Veridian, and it looks fine. Even if entire blocks of text are excluded during the OCR process (which we often see) the problem is invisible to users. That text is of course not discoverable with search systems, but nobody can tell what their search is not finding…
Incorrect coordinates and/or poor or missing text blocks do matter though when using Veridian’s OCR Text Correction feature, as it needs accurate information about where on the page each block of text appears. And some of the more interesting ideas for future use of digitized newspapers are difficult or impossible if the underlying data is poor.
Likewise, incorrect ordering of the OCR text makes it difficult to re-use or re-purpose that text. Even if all the text on the page is perfect (e.g. if users have corrected it) those using a screenreader to access the collection won’t be able to make sense of it if all the text isn’t in the correct order. Likewise the text is of much less value when exported and re-used in other systems if it isn’t in correct reading order.
The Veridian Solution
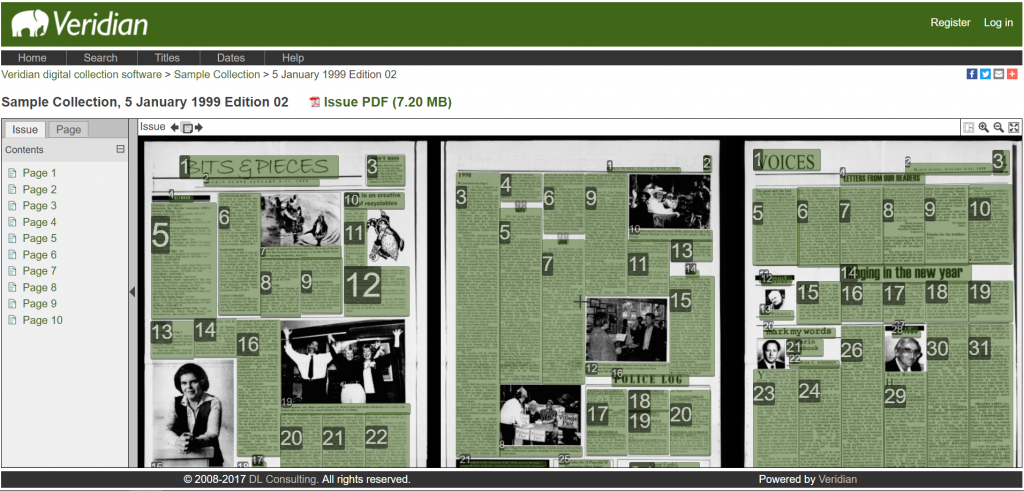
In order to avoid these “hidden errors”, our solution is to make them visible so they can be picked up as part of the data conversion and QA process. This solution has helped us identify many widespread quality issues and has been a very useful tool to raise the quality of page-level METS/ALTO. Because of that, as of August 2017, it has been implemented as a standard feature in Veridian.
The Veridian QA view (the ability to visualize ALTO XML) allows Veridian collection administrators to inspect the underlying ALTO data once they are ingested into Veridian. This hopefully can help all of those using Veridian to communicate better with their data conversion vendors to produce better quality page-level METS/ALTO.